Theodosius - Jit linker, Symbol Mapper, and Obfuscator
Repository: https://git.back.engineering/_xeroxz/Theodosius/
Doxygen: https://docs.back.engineering/theo/
Table Of Contents
- Credits
- Introduction and Preamble
- LLVM IR Level Obfuscation
- Bin2Bin Obfuscation
- Linker Level Obfuscation
- Brief Overview Of Theodosius
- Theodosius Internals
- Theodosius Example
- Creating A Pass
- Closing Words and Conclusion
Credits and Contributions
-
David Torok, reviewing the post and helping me better structure my thoughts.
-
Cody Dresel, reviewing post, feedback to create pros/cons list(s).
-
Duncan Ogilvie (mrexodia), cmkr related help and input.
Introduction and Preamble
Existing software protection frameworks typically operate at a small range of compilation levels. The highest level of obfuscation typically operates upon source code directly (source2source), the second highest level is LLVM IR (via optimization passes), and the third and final most common is upon the native binary image (bin2bin).
In this post I will present a framework that works to obfuscate code at the linker level. I will talk about the implications of obfuscating code at such a level and why it’s not really applicable for a commercial software product. I will also discuss the compilation process of C/C++ code to aid in the explanation of where this framework fits.
There is lots of fun to be had at the linker level as you have full control over the placement of symbols, and said code can have the pleasure of being obfuscated by all other levels detailed above (source2source, IR level, and bin2bin). The linker level also acts as a great stepping stone to bin2bin type obfuscation as much of the file formatting is the same. I highly recommend writing obfuscation at the linker level prior to directly writing anything for native binary images.
Lastly, I would like to state that this project is not even close to a competitor to any existing public code obfuscation framework. Infact, I would much rather point you to existing LLVM IR obfuscation than my own project as it is not capable of capturing semantics, but rather, it excels in native instruction substitution, native instruction virtualization (will be demonstrated in a later post), and symbol placement (mixing code and data). Again, It would be illogical for me to market or present this framework as anything other than a proof of concept, and a fun toy. In addition I want to truly drive home the point that I am not releasing a code obfuscator, but a code obfuscation framework. The code I am releasing is only limited by your imagination, it is not a rigid final product, but an open book, clearly documented. I find it important to make this clear, in text, so that my intent or implications are not falsely interpreted. With that out of the way, I humbly present an obfuscation framework of which operates at the linker level.
In sum, and contextual points for the rest of the post:
- Theodosius is an obfuscation framework which operates at the linker level (operates upon COFF and lib files). It is not a software protector itself, just a framework.
- Theodosius does not capture the semantics of the code, nor does it generate control flow graphs, basic blocks, or other higher level abstractions of native routines. This is out of the scope of the framework itself, but could be implemented in obfuscation passes.
- Theodosius intends to map code and data directly into virtual memory rather than generating a new COFF file. However, generation of a new COFF file is possible. The code responsible for the creation of a new COFF file is out of the scope of the framework itself and should be implemented by whomever inherits Theodosius.
- Theodosius is intended to only work with MSVC compatible COFF files.
- Theodosius is intended to only work with 64bit x86 instructions.
- Theodosius has no concept or support for SEH, CET, jump tables, or thread local storage. Refer to the readme as to how to generate code that will work with Theodosius.
LLVM IR Level Obfuscation
When considering an obfuscation that utilises LLVM IR, typically this means you must recompile your project using clang in addition to the obfuscation pass (LLVM-Obfuscator). This can imply restrictions upon the end consumer such that they may consider other options, however the inverse is true, a native instruction/file format agnostic obfuscation method could provide a “one size fits all” solution. A good application for such a thing could be android native binaries (shared objects) which can be of arm, arm64, and even x86 (some phones run x86). This, however, is not the only application of LLVM IR for obfuscation.

Another method to get at obfuscation via LLVM IR would be to use mcsema on a completely compiled binary. This would allow you to lift an entire binary to LLVM IR where you could then run obfuscation passes upon it prior to recompilation. This would remove the need to recompile source code to achieve obfuscation, therefore less integration required. This however raises questions in terms of the ability of mcsema to semantically represent x86 in terms of LLVM IR instructions. In addition, how well it can preserve things such as SEH which is more of an operating system/binary level type concept. After all, LLVM IR must respect its obligations to being agnostic.
Pros of obfuscating code at the LLVM IR level
- Agnostic of native instruction set and therefore offering obfuscation for any target that LLVM can compile too.
- The IR represents the semantics of the underlying code and therefore more intelligent and complex obfuscation can be created. Such is the case for MBA and CFG.
- Code obfuscated by LLVM IR can be further obfuscated by bin2bin and linker level obfuscation.
Cons of obfuscating code at the LLVM IR level
- Code (most likely) will need to be recompiled with clang in addition to the obfuscation pass.
- Integration into the compilation process can cause a headache for the project manager as the project will have to tailor its compiler to clang.
Bin2Bin Obfuscation
Binary to binary obfuscation takes away the annoyance and complications of incorporating anything into the compilation process of your project. However bin2bin is not trivial at all and usually is done incorrectly. In addition, bin2bin obfuscators are typically “dumb” in the sense that they are unable to capture the semantics of a function. Consider VMProtect, which is bin2bin, the three main obfuscation techniques offered by said product are: deadstore obfuscation, opaque branching obfuscation, and most significantly, native instruction virtualization (with MBA to further obscure the arithmetic done inside of the virtual machine). All three of these obfuscation techniques do not require knowledge of the function’s semantics. In comparison, OLLVM’s control flow flattening requires semantic awareness of a function to rewrite its control flow (branches) into a while loop with a switch case.

Additionally, bin2bin requires intimate knowledge of the native file format and the native instruction set. Moreover, knowledge of processor security features which the operating system may utilise must be taken into consideration. Such is the case for CET (for x86 processors) which aims to make ROP exploits a thing of the past by utilising a shadow stack to keep track of return addresses. This places restrictions on how software protectors can obfuscate control flow in terms of the RET instruction. As we speak VMProtect is not CET compatible, for there VMEXIT handler essentially uses the RET instruction as a substitute for the native CALL instruction.
vmexit_handler+0x0: 48 89 ec mov rsp,rbp
vmexit_handler+0x3: 58 pop rax
vmexit_handler+0x4: 5b pop rbx
vmexit_handler+0x5: 41 5f pop r15
vmexit_handler+0x7: 5b pop rbx
vmexit_handler+0x8: 58 pop rax
vmexit_handler+0x9: 41 5b pop r11
vmexit_handler+0xb: 5f pop rdi
vmexit_handler+0xc: 41 58 pop r8
vmexit_handler+0xe: 5a pop rdx
vmexit_handler+0xf: 41 59 pop r9
vmexit_handler+0x11: 41 5a pop r10
vmexit_handler+0x13: 41 5c pop r12
vmexit_handler+0x15: 5d pop rbp
vmexit_handler+0x16: 9d popf
vmexit_handler+0x17: 59 pop rcx
vmexit_handler+0x18: 59 pop rcx
vmexit_handler+0x19: 41 5e pop r14
vmexit_handler+0x1b: 5e pop rsi
vmexit_handler+0x1c: 41 5d pop r13
vmexit_handler+0x1e: c3 ret
you can read more details here: https://back.engineering/17/05/2021/#vm_exit
It is my opinion that not a single public bin2bin software protector is worth your money. Regardless of the lack of decent public tooling for VMProtect or Oreans Code Virtualizer, there is private tooling for these protectors. These protectors pose little to no difficulty against a team of educated reverse engineers. I drew this conclusion myself when creating my tooling for VMProtect 2 and VMProtect 3. Considering that I was a lone reverse engineer with little to no prior experience with deobfuscation/devirtualization when I took the challenge upon myself to create useful tooling against VMProtect, which I was arguably successful in doing.
Due to my research I have had the ability to see a wide range of private tooling, all of which massively nullify the protections of these public protectors. Do not be lulled into thinking that these protectors are difficult or impossible to remove simply because you cannot clone a repository off of github to remove the obfuscation.
My claims can and will be backed up as time progresses. For now, I will end this passage with the following: recently there was a full devirtualization of BattlEye’s kernel component (which is protected with VMProtect 3). This devirtualization is unparalleled to public tooling and restores the image almost to near original assembly. A link to this image is provided below.
https://www.unknowncheats.me/forum/downloads.php?do=file&id=36229
Furthermore, it is my opinion that Code Virtualizer (CV) and the products built upon it, such as Themida and WinLicense, are not viable products for CV has an abundance of semantic inaccuracies in its native instruction virtualization, this only gets exacerbated by their nested virtualization. The only obfuscation that is worth your money is obfuscation that is semantically correct. Even more, Code Virtualizer cannot handle switch cases without macros, which even VMProtect has been able to completely handle since version 2.x.
“When the code is virtualized, the jump goes into a virtualized (garbage) code and it produces exception."
Source: https://www.oreans.com/help/cv/hm_faq_can-vm-macros-protect-switch-s.htm
Additionally, macros must be used for try-except/try-finally blocks. You may be tempted to think that this is a feature to allow the end user to control what should be protected. Rather, it is poor engineering that requires the end user to provide information so that it can barely work.
“You have to insert VM macros in try-finally clauses in the same was as you do for try-except."
Source: https://www.oreans.com/help/cv/hm_faq_i-have-seen-that-insertion-of-.htm
Moreover, Code Virtualizer only allows a single thread inside of the virtual machine at a time. This is because the virtual machines context is not allocated upon the stack like VMProtect’s virtual machine context is. Code Virtualizer utilises a spinlock on every virtual machine enter to ensure only a single thread is executing inside of the virtual machine.

For multi threaded programs this completely nullifies the purpose of having more than a single thread. With all of this in mind, it is truly baffling that Code Virtualizer offers protection for Windows kernel drivers. I hope no company is fooled into using this protector to obfuscate a kernel component.
I find it interesting that Oreans is willing to market such a product regardless of its known issues. I think their engineers are smart enough to know their software protectors shortcomings, yet they still present their product as though it offers unparalleled protection. Definitely raises the question as to who their products target? No legitimate company would use Code Virtualizer if they knew the risks entailed. I think what this all boils down too is that Oreans is taking advantage of ignorant customers selling them a product that their own engineers know is not stable, extremely slow, and far behind other protectors. They use their feature list to impress potential buyers when in reality, none of the features matter if none of it is stable.
Have a look at the feature list yourself: https://www.oreans.com/codevirtualizer.php#two
My negative opinions of existing bin2bin protectors has been further amplified as of recently. This is due to the fact that I have witnessed technology in development that addresses all of the complex difficulties related to bin2bin.
Pros of bin2bin
- Little to no compilation requirements/integration
- Much easier to integrate into a project
Cons of bin2bin
- Extremely difficult to do correctly. Not a single public bin2bin protector is worth your money as I explain in the paragraphs above.
- Requires intimate knowledge of the native file format
- Requires intimate knowledge of the instruction set
- Requires intimate knowledge of the processor security features and how the operating system may utilise them (CET, data alignment checks/AC Bit in EFLAGS).
- Typical bin2bin obfuscation is “dumb” and cannot/does not capture semantics.
Linker Level Obfuscation
So considering the above two levels of obfuscation, where does a “linker level” obfuscation framework lay? The linker level gets the short end of both sticks from bin2bin and IR level. It requires integration into the compilation process and it is bound to a single instruction set. In addition this level of obfuscation requires intimate knowledge of the COFF file format.
However, regardless of these requirements, the linker level offers a unique ability that other levels of obfuscation cannot offer. The linker level allows you to freely position code and data how you see fit. Additionally, code can be obfuscated at the IR level prior to further being obfuscated at the linker level. You can envision obfuscation at the linker level as being synonymous with bin2bin with the added support of symbol placement.

If it’s not clear by now, doing obfuscation at the linker level is not viable in a commercial software protector manner. For we would have seen such a product already due to market forces, there is simply no demand for this type of product. Instead, I find obfuscation at this level to be a fantastic stepping stone to bin2bin obfuscation. For me and others, this is a great place to learn.
Pros of linker level obfuscation
- Control over symbol placement
- Control over linking symbols together
Cons of linker level obfuscation
- All the same cons as bin2bin
- Requires integration into the compilation process
Brief Overview Of Theodosius
Theodosius operates upon COFF files. It substitutes the role of the linker and instead of generating a native file it allows you, the programmer, to obfuscate symbols, control over symbol placement, and lastly control over both static and dynamic linking. There are three main modules to Theo, decomposition (decomp), obfuscation (obf), and recomposition (recomp).
Decomposition Module
The first component, decomposition, is used to break down COFF files into manageable data structures which contain metadata about COFF symbols (data symbols, functions, sections, etc). These metadata objects are then used throughout the rest of the framework. The most important classes used for decomposition are detailed below. They are also defined in the doxygen generated for this project.
- theo::decomp::decomp_t class contains wrapper code to decompose a lib file. It is the highest level class used in decomposition.
- theo::decomp::symbol_t class is extremely important to understand as it is used to describe all symbols.
Obfuscation Module
The second module in Theo is the obfuscation system. The obfuscation system consists of a singleton engine (theo::obf::engine_t), and a base class pass template (theo::obf::pass_t). Obfuscation passes are created by defining a class that inherits theo::obf::pass_t, overloading the virtual run method, and finally adding it to the obfuscation engine. The responsibility of adding passes to the engine rests upon the code base that inherits Theo. In other words, Theo does not run any passes by default, it’s entirely up to the programmer submoduling Theo to set up the passes and their order. The most important classes used for obfuscation are detailed below. They are also defined in the doxygen generated for this project.
- theo::obf::engine_t this is a singleton class which is used to keep track of passes and their order of execution. You can get a reference to this object by calling theo::obf::engine_t::get. You can then add passes with the add_pass function. Here is an example of that:
// order matters, the order in which the pass is added is the order they
// will be executed!
//
auto engine = theo::obf::engine_t::get();
// add in our hello world pass here
//
engine->add_pass(theo::obf::hello_world_pass_t::get());
// add the rest of the passes in this order. this order is important.
//
engine->add_pass(theo::obf::reloc_transform_pass_t::get());
engine->add_pass(theo::obf::next_inst_pass_t::get());
engine->add_pass(theo::obf::jcc_rewrite_pass_t::get());
- theo::obf::pass_t is the base class for all passes. There is a single virtual method, run, that must be overloaded when inheriting this class. In addition, it is highly suggested that you make all passes singleton with a private constructor. Consider the following code for jcc_rewrite_pass:
class jcc_rewrite_pass_t : public pass_t {
// call the parent constructor and tell it we only want “instruction” type symbols…
explicit jcc_rewrite_pass_t() : pass_t(decomp::sym_type_t::instruction) {}
public:
static jcc_rewrite_pass_t* get();
void run(decomp::symbol_t* sym);
};
Recomposition Module
The last module to Theo is recomposition. This module is responsible for allocating space for symbols, resolving references to symbols, and copying symbols into memory. All three, allocation, symbol resolution, and memory copying are completely determined by the programmer. This allows the framework to be extremely open ended in its application. Symbol resolution within the COFF files themselves is handled by Theo. Any external symbols call upon the supplied resolver lambda function the programmer provides the framework.
The most important classes/data types used for recomposition are detailed below. They are also defined in the doxygen generated for this project.
- theo::recomp::allocator_t - a function which is called by recomp_t to allocate space for a symbol.
- theo::recomp::copier_t - a function which is called by recomp_t to copy symbols into memory.
- theo::recomp::resolver_t - a function which is called by recomp_t to resolve external symbols.
- theo::recomp::recomp_t - the main class responsible for recomposition.
Theodosius Internals
Let’s move onto some of the internals of Theodosius as I think it’s important to discuss such things as how relocations are handled, how routines are split into individual instructions, how function length is determined, and how .rdata/.data section symbols are handled.
To begin, when the compiler generates a COFF file, each symbol will have its own section up until there are 65535 sections, after which symbols will share sections with liked characteristics. For code/data/rdata/bss, this means symbols can have their own section and/or share a section with other symbols depending upon how many other symbols have already been declared in the COFF file. Although Theodosius aims to provide control over symbol placement, it will not split .data/.rdata/.bss symbols apart which reside in the same section. The reason being: some data structures may have multiple data symbols referencing inside of them.
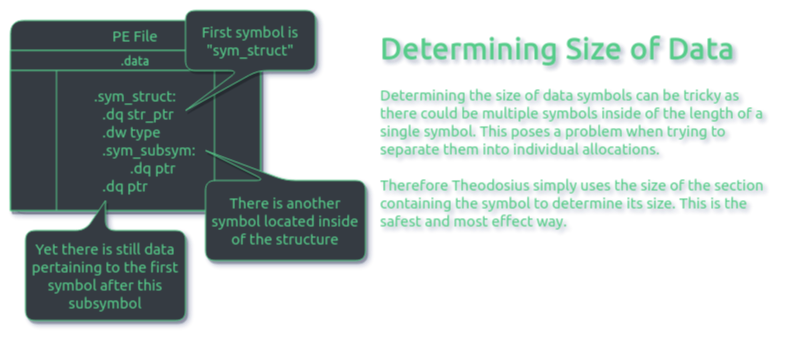
This makes it extremely difficult to determine the actual size of the data. For this reason, data symbol sizes are calculated by the size of the section that contains them. Lastly, BSS symbols (zero initialised symbols) are handled in the same manner as other .data/.rdata symbols.

Code on the other hand can be calculated by determining the distance between the start of the function and the beginning of the next symbol in the same section. If there are no other code symbols in the section then the size of the section itself is used as the size of the function. Determining size of functions in this manner offers a massive performance boost in comparison to recursively disassembling every function to determine the very last instruction. However, the method that Theo performs includes padding instructions (such at int3’s) into the function and its size.

During the decomposition stage of Theo a symbol is determined either code, data, or bss by looking at the characteristics of symbol type (it does not use section characteristics to deduce symbol type).
if (sym->derived_type == coff::derived_type_id::function &&
sym->storage_class != coff::storage_class_id::external_definition &&
sym->has_section()) {
auto scn = img->get_section(sym->section_index - 1);
auto dcmp_type =
scn->name.to_string(img->get_strings()) == INSTR_SPLIT_SECTION_NAME
? decomp::sym_type_t::instruction
: decomp::sym_type_t::function;
auto fn_size = next_sym(img, scn, sym);
auto fn_bgn = scn->ptr_raw_data + reinterpret_cast<std::uint8_t*>(img) +
sym->value;
std::vector<std::uint8_t> fn(fn_bgn, fn_bgn + fn_size);
decomp::routine_t rtn(sym, img, scn, fn, dcmp_type);
auto syms = rtn.decompose();
m_syms->put_symbols(syms);
}
The above code is wrapper code contained inside of the decomp_t class to handle decomposition of functions. It’s important to understand that any function that is stored inside of a section with the name .split will result in the functions decomposition into individual instructions rather than a single symbol containing the entire function.
Another thing to note is that the size of the function is determined by subtracting the address of the next symbol in the same section. This solves the problem of multiple functions located inside of the same section. If there is only a single symbol/function in the section then the address of the end of the section is returned.
auto fn_size = next_sym(img, scn, sym);
auto fn_bgn = scn->ptr_raw_data + reinterpret_cast<std::uint8_t*>(img) +
sym->value;
std::vector<std::uint8_t> fn(fn_bgn, fn_bgn + fn_size);
Let’s take a closer look into how functions are decomposed as it will answer how relocations are handled. When a function is decomposed into a sequence of theo::decomp::symbol_t’s any relocations inside of that routine are passed along to the symbol_t. However relocations are rebased to be from the beginning of the routine (or instruction).
std::vector<recomp::reloc_t> relocs;
auto scn_relocs = reinterpret_cast<coff::reloc_t*>(
m_scn->ptr_relocs + reinterpret_cast<std::uint8_t*>(m_img));
for (auto idx = 0u; idx < m_scn->num_relocs; ++idx) {
auto scn_reloc = &scn_relocs[idx];
// if the reloc is in the current function...
if (scn_reloc->virtual_address >= m_sym->value &&
scn_reloc->virtual_address < m_sym->value + m_data.size()) {
auto sym_reloc = m_img->get_symbol(scn_relocs[idx].symbol_index);
auto sym_name = symbol_t::name(m_img, sym_reloc);
auto sym_hash = decomp::symbol_t::hash(sym_name.data());
relocs.push_back(
recomp::reloc_t(scn_reloc->virtual_address - m_sym->value,
sym_hash, sym_name.data()));
}
}
result.push_back(decomp::symbol_t(
m_img, symbol_t::name(m_img, m_sym).data(), m_sym->value, m_data,
m_scn, m_sym, relocs, sym_type_t::function));
The same logic applies to instructions, however relocations are rebased to the beginning of the instruction.
Recursive Symbol Dependency Check
Another important topic to discuss is how Theo determines which symbols are used and which symbols are not. When you compile a static library, all functions, regardless if they are referenced at all in the C/C++ source code will be compiled into the static library. This makes sense as the functions needed when statically linking with external code is unknown at the time of compilation of the static library itself, therefore all functions are included. Mapping all of these symbols is wildly inefficient as you can imagine. Therefore Theo implements a recursive symbol walk to determine all of the symbols that are used.
This is not a new concept as linkers themselves implement this very same functionality. Other forms of this can be observed in the process of decompilation, where code and data are uncovered by recursively following call instructions and tracking all references to data and functions (IDA does this).
Consider the following code (main.cpp):
void t2()
{
puts(“this func never gets called”);
}
void t1(const char* str)
{
puts(“T1 is called”);
puts(str);
}
int main()
{
t1(“hello world”);
}
The above code will generate 7 (and some extra) symbols into a single COFF file named “main.obj”
- int main in a
.textsection - void t1 in a
.textsection - void t2 in a
.textsection - A symbol for “puts”, with a storage class of
IMAGE_SYM_CLASS_EXTERNAL, and a section index of 0 indicating that the symbol is not located inside of the COFF file. - “hello world” string in a
.rdatasection. - “T1 is called” string in a
.rdatasection. - “this func never gets called” string in a
.rdatasection
Now consider that “t2” is never called by any code in the file but it will still be present in the generated COFF and archive (lib) file. It would be a waste of resources for Theo to map these unused symbols. For this reason I have implemented the following algorithm to extract the used symbols given an entry point.
std::uint32_t decomp_t::ext_used_syms(const std::string&& entry_sym) {
// start with the entry point symbol...
std::optional<sym_data_t> entry = get_symbol(entry_sym.data());
// if the entry point symbol cant be found simply return 0 (for 0 symbols
// extracted)...
if (!entry.has_value())
return 0u;
// little memoization for perf boost... :^)
std::set<coff::symbol_t*> cache;
const auto finding_syms = [&]() -> bool {
// for all the symbols...
for (auto itr = m_used_syms.begin(); itr != m_used_syms.end(); ++itr) {
auto [img, sym, size] = *itr;
// if the symbol has a section and its not already in the cache...
if (sym->has_section() && !cache.count(sym) && size) {
auto scn = img->get_section(sym->section_index - 1);
auto num_relocs = scn->num_relocs;
auto relocs = reinterpret_cast<coff::reloc_t*>(
scn->ptr_relocs + reinterpret_cast<std::uint8_t*>(img));
// see if there are any relocations inside of the symbol...
for (auto idx = 0u; idx < num_relocs; ++idx) {
auto reloc = &relocs[idx];
// if the reloc is inside of the current symbol...
if (reloc->virtual_address >= sym->value &&
reloc->virtual_address < sym->value + size) {
// get the symbol for the relocation and add it to the m_used_symbol
// vector...
auto reloc_sym = img->get_symbol(reloc->symbol_index);
auto sym_name = symbol_t::name(img, reloc_sym);
entry = get_symbol(sym_name);
// if the symbol already exists in the m_used_syms vector then we
// return out of this function and continue looping over all symbols
// recursively...
if (m_used_syms.emplace(entry.value()).second)
return true; // returns to the for loop below this lambda. the
// return true here means we added yet another
// symbol to the "m_used_syms" vector...
}
}
// cache the symbol so we dont need to process it again...
cache.emplace(sym);
}
}
return false; // only ever returns false here when every single symbol
// inside of m_used_syms has been looked at to see if all of
// its relocation symbols are included in the m_used_syms
// vector (meaning we got all the used symbols...)
};
// add the entry point symbol...
m_used_syms.emplace(entry.value());
// keep recursively adding symbols until we found them all..
for (m_used_syms.emplace(entry.value()); finding_syms();)
;
return m_used_syms.size();
}
The last section of information regarding the inner workings of Theo will discuss some intentionally embedded obfuscation and techniques to identify which routines are split up into individual instruction symbols.
Firstly, although Theo could potentially offer the ability to obfuscate code and generate a new COFF file, it was originally created with the intent of mapping and running the code straight from the COFF file after executing all obfuscation passes. For this reason, there exists a few noticeable design decisions which favour that intent.
Secondly, the theo::recomp::reloc_t structure contains information pertaining to obfuscating the address of relocations. When resolving relocations is performed, Theo will loop through a vector of transformations contained inside of the reloc_t structure, executing each transformation upon the address of the relocation, ultimately encrypting it. This is a hardcoded concept that doesn’t necessarily need to be utilised, but it is there if needed.
Thirdly, by default, allocation and resolving symbols is done in terms of linear virtual addresses. Therefore, by default, any code generated by Theodosius is not position independent. It is feasible to circumvent this however with a pass that rewrites relocations to be rip relative.
Lastly, in regards to breaking functions into individual instruction symbols, Theo does this on the basis of the section name that contains the function itself. Any function which is declared inside of a section with the name .split will result in the function’s decompilation into individual instruction symbols.
Theodosius Internal Passes
Theodosius contains a few internal passes. These passes handle boilerplate scenarios and can be built on top of easily. Additionally, these passes are optional and don’t need to be utilised.
The three internal obfuscation passes offered are the following:
next_inst_pass_t
This pass is used to generate transformations and jmp code to change RIP to the next instruction. Given the following code (get pml4 address from cr3):
get_pml4:
mov rax,0xfff ; 0: 48 c7 c0 ff 0f 00 00
not rax ; 7: 48 f7 d0
mov rdx,cr3 ; a: 0f 20 da
and rdx,rax ; d: 48 21 c2
mov rax,rdx ; 10: 48 89 d0
ret ; 1C: c3
This pass will break up each instruction so that it can be anywhere in a linear virtual address space. This pass will not work on rip relative code, however clang will not generate such code when compiled with -mcmodel=large.
get_pml4@0:
mov rax, 0xFFF
push [next_inst_addr_enc]
xor [rsp], 0x3243342
; a random number of transformations here...
ret
next_inst_addr_enc:
; encrypted address of the next instruction goes here.
get_pml4@7:
not rax
push [next_inst_addr_enc]
xor [rsp], 0x93983498
; a random number of transformations here...
ret
next_inst_addr_enc:
; encrypted address of the next instruction goes here.
This process is continued for each instruction in the function. The last instruction, RET, will have no code generated for it as there is no next instruction.
This pass also only runs at the instruction level, theodosius internally breaks up functions inside of the .split section into individual instruction symbols. This process also creates a pseudo relocation which simply tells this pass that there needs to be a relocation to the next symbol. The offset for these pseudo relocations is zero.
jcc_rewrite_pass
This pass rewrites rip relative jcc’s so that they are position independent.
Given the following code:
jnz label1
; other code goes here
label1:
; more code here
The jnz instruction will be rewritten so that the following code is generated:
jnz br2
br1:
jmp [rip] ; address after this instruction contains the address
; of the instruction after the jcc.
br2:
jmp [rip] ; address after this instruction contains the address of where
; branch 2 is located.
It’s important to note that other passes will encrypt (transform) the address of the next instruction. There is actually no jmp [rip] either, push/ret is used.
reloc_transform_pass
This pass is like the next_inst_pass, however, relocations are encrypted with transformations instead of the address of the next instruction. This pass only runs at the instruction level and appends transformations into the reloc_t object of the instruction symbol.
Given the following code:
mov rax, cs:MessageBoxA
This pass will generate a random number of transformations to encrypt the address of “MessageBoxA”. These transformations will then be applied by theodosius internally when resolving relocations.
mov rax, enc_MessageBoxA
xor rax, 0x389284324
add rax, 0x345332567
ror rax, 0x5353
Theodosius Example
Theodosius comes with a demonstration project and a few static libraries for testing purposes. These are meant to be built on Windows platforms only, however Theodosius itself can compile for linux (follow the readme for instructions).
int main(int argc, char* argv[]) {
if (argc < 2)
return -1;
// read in lib file...
std::ifstream f(argv[1], std::ios::binary);
auto fsize = fs::file_size(fs::path(argv[1]));
std::vector<std::uint8_t> fdata;
fdata.resize(fsize);
f.read((char*)fdata.data(), fsize);
LoadLibraryA("user32.dll");
LoadLibraryA("win32u.dll");
// declare your allocator, resolver, and copier lambda functions.
//
theo::recomp::allocator_t allocator =
[&](std::uint32_t size,
coff::section_characteristics_t section_type) -> std::uintptr_t {
return reinterpret_cast<std::uintptr_t>(VirtualAlloc(
NULL, size, MEM_COMMIT | MEM_RESERVE,
section_type.mem_execute ? PAGE_EXECUTE_READWRITE : PAGE_READWRITE));
};
theo::recomp::copier_t copier = [&](std::uintptr_t ptr, void* buff,
std::uint32_t size) {
std::memcpy((void*)ptr, buff, size);
};
theo::recomp::resolver_t resolver = [&](std::string sym) -> std::uintptr_t {
auto loaded_modules = std::make_unique<HMODULE[]>(64);
std::uintptr_t result = 0u, loaded_module_sz = 0u;
if (!EnumProcessModules(GetCurrentProcess(), loaded_modules.get(), 512,
(PDWORD)&loaded_module_sz))
return {};
for (auto i = 0u; i < loaded_module_sz / 8u; i++) {
wchar_t file_name[MAX_PATH] = L"";
if (!GetModuleFileNameExW(GetCurrentProcess(), loaded_modules.get()[i],
file_name, _countof(file_name)))
continue;
if ((result = reinterpret_cast<std::uintptr_t>(
GetProcAddress(LoadLibraryW(file_name), sym.c_str()))))
break;
}
return result;
};
// init enc/dec tables only once... important that this is done before adding
// obfuscation passes to the engine...
//
xed_tables_init();
// order matters, the order in which the pass is added is the order they
// will be executed!
//
auto engine = theo::obf::engine_t::get();
// add in our hello world pass here
//
engine->add_pass(theo::obf::hello_world_pass_t::get());
// add the rest of the passes in this order. this order is important.
//
engine->add_pass(theo::obf::reloc_transform_pass_t::get());
engine->add_pass(theo::obf::next_inst_pass_t::get());
engine->add_pass(theo::obf::jcc_rewrite_pass_t::get());
std::string entry_name;
std::cout << "enter the name of the entry point: ";
std::cin >> entry_name;
// create a theo object and pass in the lib, your allocator, copier, and
// resolver functions, as well as the entry point symbol name.
//
theo::theo_t t(fdata, {allocator, copier, resolver}, entry_name.data());
// call the decompose method to decompose the lib into coff files and extract
// the symbols that are used. the result of this call will be an optional
// value containing the number of symbols extracted.
//
auto res = t.decompose();
if (!res.has_value()) {
spdlog::error("decomposition failed...\n");
return -1;
}
spdlog::info("decomposed {} symbols...", res.value());
auto entry_pnt = t.compose();
spdlog::info("entry point address: {:X}", entry_pnt);
reinterpret_cast<void (*)()>(entry_pnt)();
}
It’s important to note that this code is from the inheritor of theodosius’s perspective. Therefore it’s the programmers responsibility to call xed_tables_init. In addition, you can see that the programmer is the one who has control over the obfuscation passes and the order in which they run.
auto engine = theo::obf::engine_t::get();
// add in our hello world pass here
//
engine->add_pass(theo::obf::hello_world_pass_t::get());
// add the rest of the passes in this order. this order is important.
//
engine->add_pass(theo::obf::reloc_transform_pass_t::get());
engine->add_pass(theo::obf::next_inst_pass_t::get());
engine->add_pass(theo::obf::jcc_rewrite_pass_t::get());
The example simply registers the built in obfuscation passes to run with the addition of the hello_world_pass_t.
Creating A Pass
To create a pass for Theodosius, one must define a class that publicly inherits the theo::obf::pass_t base class. This class that is defined should be a singleton class with a private constructor which invokes the parent constructor. Refer to the following code:
class hello_world_pass_t : public pass_t {
hello_world_pass_t() : pass_t(decomp::sym_type_t::all) {
spdlog::info("created hello world pass...");
}
public:
static hello_world_pass_t* get() {
static hello_world_pass_t obj;
return &obj;
}
void run(decomp::symbol_t* sym) {
spdlog::info("[hello_world_pass_t] symbol name: {}, symbol hash: {}",
sym->name(), sym->hash());
}
};
When invoking the parent constructor in the private default constructor of your pass you must provide which symbols you want your pass to operate upon. In the example above the hello_world_pass_t operates upon all symbols. A list of all symbols your pass can operate upon are listed below:
- theo::decomp::sym_type_t::function
- theo::decomp::sym_type_t::instruction
- theo::decomp::sym_type_t::data
- theo::decomp::sym_type_t::section
- theo::decomp::sym_type_t::all
This concludes the section in regards to demonstration of theodosius. You can further refer to the code in the project if you would like to learn more. Links to related documents are linked below.
- https://docs.back.engineering/theo/dd/d70/md_examples_demo__demo__example__using__theo.html
- https://docs.back.engineering/theo/d9/d18/classtheo_1_1obf_1_1engine__t.html
- https://docs.back.engineering/theo/d4/dad/classtheo_1_1obf_1_1pass__t.html
- https://docs.back.engineering/theo/df/d0a/main_8cpp.html
Closing Words and Conclusion
In conclusion, Theodosius is a linker level obfuscation framework which allows a programmer to mess about with native instructions and symbol placement. The framework contains a well documented pass system, and it even comes with an example.
I originally wanted to create a framework that I could use to recreate VMProtect obfuscation techniques to better explain how they work. In my last VMProtect related post I stated the following:
“Lastly, during my research of VMProtect 2, there has been a subtle urge to reimplement some of the obfuscation and virtual machine features myself in an open source manner to better convey the features of VMProtect 2. However, after much thought, it would be more productive to create an obfuscation framework that would allow for these ideas to be created with relative ease."
I will conclude this post by stating that although publicly researching software protectors is fun, it can be damaging to my own image as the tooling can be used in a negative manner. For that I will continue my research in private and publicly focus more on the creation of obfuscation/software protection. As to my comments in regards to Themida/Code Virtualizer they are not meant to be slander, rather constructive criticism. All of the concerns I have raised are legitimate and based in reality.